When did a loss function become necessary?
Probably everyone here knows what goes on during the training of a deep-learning neural network. However, allow me to quickly refresh your memory. To get the best performance out of our deep learning models, we employ the gradient descent optimization technique during the training phase of deep learning neural network construction. This optimization method iteratively estimates model error. The loss of the model must now be calculated, and an appropriate error function (Loss Functions in Deep Learning) must be selected to update the model’s weights and bring the loss down in preparation for further evaluation.
With any luck, you now have a rough sense of what goes into training a deep neural network. Let’s keep going and see if we can get a clearer picture.
Can You Explain the Concept of a Loss Function?
A loss function measures how well an algorithm reproduces the training data.
Optimization methods evaluate the objective function. Now we can choose whether to maximize the goal function and achieve the best possible score or minimize it and achieve the lowest possible score.
In deep learning neural networks, the goal is to reduce error.
To what extent are Loss Functions and Cost Functions distinct?
There’s a slight but crucial distinction between the cost function and the loss function.
We refer to it as a Loss Functions in Deep Learning when we only have a single training example. The error function is another name for it. Instead, a cost function is the overall average loss in the training set.
Now that we understand what a loss function is and why it’s important, we need to know when and how to use it.
Diverse Loss Functions

In general, we can classify Loss Functions in Deep Learning into one of three broad categories, as indicated below.
Loss Functions for Regression
Partial Loss Modified Root Mean Square
The ratio of the Mean Squared Error to the Logarithm of the Error
The margin of Error means Absolute
Losses on L1 and L2
Negative Huber Effect
The Loss of Pseudo-Hubert Momentum
Loss Functions for Binary Classification
Hinge Loss, Squared, Binary Cross-Entropy
Loss Functions for Multiple Classifications
Loss of Cross Entropy Across several Classes
Sparse Cross-entropy loss for several classes
A Negative Loss of Kullback-Leibler Divergence
Forms of Loss in Regression
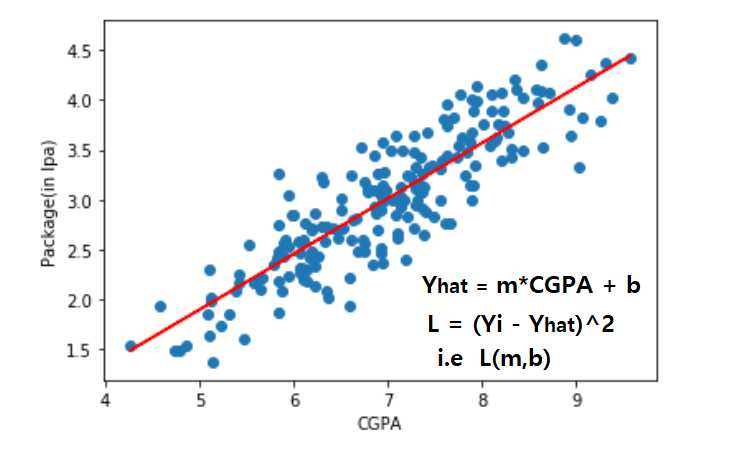
You should be very comfortable with linear regression issues by now. A linear relationship between a dependent variable Y and a set of independent variables X is the focus of the Linear Regression problem. This means that to find the least inaccurate model, we effectively fit a line through this space. Predicting a numerical variable is what a regression problem is all about.
I’ll do my best to introduce you to a few of the more common Loss Functions in Deep Learning here, and I intend to devote more time to describing the others in future articles.
- The margin of Error, Squared
Experiencing both L1 and L2 loss
- L1 and L2 loss functions reduce errors in machine learning and deep learning.
- Least Absolute Deviations, or L1, is another name for the L1 loss function. The L2 loss function, usually known as LS for short, minimizes the sum of squared errors.
- First, a quick primer on the difference between the two Loss Functions in Deep Learning
The function of loss at level L1
It reduces the error between real and expected numbers.
The average of these absolute errors is the cost, also known as l1 loss function (MAE).
Loss Function for L2 Spaces
Error, the total of measured and predicted differences, is decreased.
The MSE cost function (MSE).
Please take into consideration that when there are outliers, the largest component of the loss will be attributable to these spots.
Consider the case where the true value is 1, the prediction is 10, the prediction value is 1000, and the prediction value of the other times is roughly 1.
TensorFlow plots of L1 and L2 loss
#loading library files
bring in NumPy as np
use tf as an import to bring in TensorFlow.
plt x pre = to. in space import matplotlib. pyplot as plt (-1., 1., 100)
For example: x actual = tf.constant(0,dtype=tf.float32).
L1 Loss = of.abs((x pre – x actual))
The formula for finding the square root of the difference between the predicted and actual values of x is l2 loss = ft. square((x pre – x actual)).
x ,l1 ,l2_ = sess.run([x pre, l1 loss, l2 loss]) with tf.Session() as sess.
plt.plot(x ,l1 ,label=’l1 loss’)
plt.plot(x ,l2 ,label=’l2 loss’)
plt.show() plt.legend() ()
Output: This is the plot that the preceding code would generate:
- Huber Deficiency
The Huber Loss method is frequently applied when solving regression issues. Huber Loss is more robust to extreme data than L2 loss (because if the residual is too large, it is a piecewise function, and loss is a linear function of the residual).
Huber loss incorporates the most advantageous aspects of both MSE and MAE. This function is quadratic for minor errors and linear otherwise (and similarly for its gradient). This parameter, called delta, is used to identify it.
The set parameter stands for the actual value y, whereas f(x) stands for the anticipated value.
The benefit of this is that the loss function is L2-norm when the residual is small, and L1-norm when the residual is high.
- a loss function based on the pseudo-Huber theorem
For each order to be differentiable, we use a smooth approximation of the Huber loss.
InsideAIML: The Pseudo-Huber Loss Function
The linear component on both sides becomes steeper as increases. The plot presented below can be used to make this observation.
- Functions of Loss for Binary Classification
Putting something into one of two categories is what we mean when we talk about binary classification. A rule is applied to the input feature vector to arrive at this categorization. Classifying whether or not rain will fall today, based on the subject line, is an example of a binary classification problem. Let’s have a look at various Loss Functions in Deep Learning that are relevant to this problem.
Deficiency in the Hinge
For example, in a scenario where the ground truth is either t = 1 or -1 and the projected value is y = wx + b, hinge loss is commonly utilized.
This is what hinge loss means in the SVM classifier:
The hinge loss is a type of loss function utilized during the classification process in machine learning. Maximum-margin classification, such as that performed by support vector machines, makes advantage of the hinge loss (SVMs). [1]
The hinge loss of a prediction y is defined as for a target output t = 1 and a classifier score y:
That is, the loss will be minimized if y approaches t.
Negative cross-entropy
In the fields of machine learning and optimization, cross-entropy can be used to characterize a loss function. The genuine probability displayed as display style p IP I, is the actual label, while the specified distribution, displayed as display style q iq I, is the expected value based on the present model. The word “cross-entropy loss” is synonymous with the term “log loss” (or logarithmic loss[1] or “logistic loss”). [3]
In particular, think of a binary regression model, which can divide observations into one of two categories (often denoted by the labels “display style 0” and “display style 1”). The model’s output for an observation given a vector of input features is probability. Logistic regression makes use of the logistic function to model probability.
During training, logistic regression often optimizes the log loss, which is the same as optimizing the average cross-entropy. So, for illustration, let’s say we have display style NN samples, and we’ve assigned indices to them using the form display style n=1, dots, Nn=1, dots, N. Then, we can calculate the mean loss function by using:
You may also hear the logistic loss referred to as the cross-entropy loss. Log loss (where 1 and 1 are the binary labels used here).
In linear regression, the gradient of the squared error loss is equal to the gradient of the cross-entropy loss. To put it another way, characterize
Negative Sigmoid Cross-entropy
For the aforementioned cross-entropy loss to apply, the anticipated value must be a probability. For most purposes, we use the formula scores=x * w+b. This number can reduce the sigmoid function’s range (0,1).
Predicted values of sigmoid far from the label loss increase are not as steep since the sigmoid function smoothes them out (compare inputting 0.1 and 0.01 with inputting 0.1, 0.01 followed by entering; the latter will have a far smaller change value).
Loss of softmax cross entropy
Softmax can convert fraction vectors into probability vectors. In this article, we explain what a softmax function is and how it works.
Similar to how the last example “squashes” a k-dimensional real number to the [0,1] range, softmax does the same for k, while additionally ensuring that the cumulative total is 1.
Cross entropy’s definition requires probability as an input. Softmax cross-entropy loss uses the softmax function to transform the score vector into a probability vector.
following the notion of cross-entropy loss.
Similarly to the previous implementations, softmax uses a vector that “squashes” k-dimensional real values to the [0,1] range, while guaranteeing that the cumulative sum is 1.
Cross entropy’s definition requires probability as an input. Both the sigmoid and softmax-cross entropy losses take the score vector and transform it into a probability vector, but the former employs the sigmoid function while the latter utilizes the softmax function.
To use the terminology of cross entropy losses definition.
Where fj is the total possible category score and FYI is the score of the ground truth class.